Obsah videa:
- charakteristiky proměnných: name (1:47), type (2:46), width (4:11), decimals (4:18), label (6:00), values (8:00), missing (15:52), columns (17:59), align (18:20), measure (18:32), role (22:01)
Video:
Odkazy:
Série videí o Dotazování a tvorbě datové matice
Pracovní prostředí SPSS
Nyní se před námi nachází prázdné datové okno. Ve skutečnosti v SPSS rozlišujeme čtyři typy oken:
- datové okno – zde si nahrajeme vstupní data a budeme pracovat s jednotlivými proměnnými
- výstupové okno (output) – zde se budou zobrazovat veškeré výsledky vaší práce
- syntaxové okno – využívá se pro práci se syntaxí, tj. pomocí speciálního jazyka určeného k zadávání příkazů SPSS
- skriptové okno – zde můžeme vytvářet skripty (programy) pro zautomatizování některých činností (např. upraví podobu tabulek v outputu, přeloží určitou část výstupu do češtiny, apod.)
Nás ale budou zajímat jen ta první dvě okna, která jsou pro naši práci nejdůležitější – datové okno a Output.
1. Datové okno
Datové okno, jak už název napovídá, slouží pro práci se vstupními daty a proměnnými. Budeme je zde definovat, kódovat a přiřazovat jim určité charakteristiky, kterými ovlivníme podobu výstupu.
V dolní části datového okna máme dvě záložky – Data View (zde máme data – jednotlivé případy) a Variable View (zde máme proměnné). Každému řádku proměnné v záložce Variable View odpovídá příslušný sloupec v záložce Data View, který bude obsahovat data jednotlivých případů (odpovědi jednotlivých respondentů na konkrétní otázku).
1.1 Variable View (Pohled na proměnné)
V řádcích máme jednotlivé proměnné – pro každou proměnnou jeden řádek. Každou proměnnou můžeme nadefinovat podle charakteristik ve sloupcích.
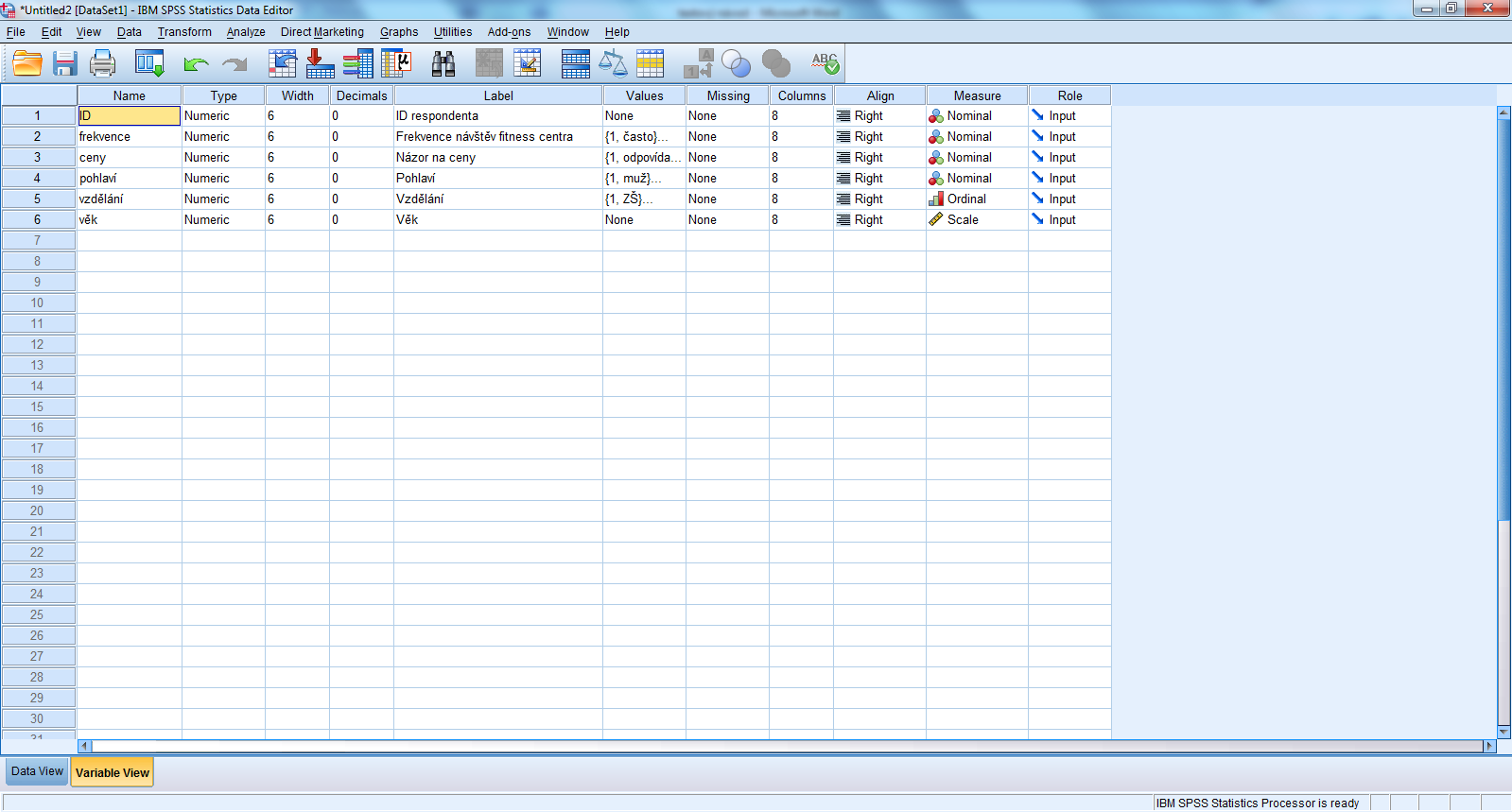
1.1.1 Name (Název)
Není nutné upravovat, je to spíš pro přehlednost. Objevuje se v pracovních oknech u jednotlivých procesů a analýz, takže by měl být krátký a výstižný. Navíc může obsahovat jen 64 znaků, nesmí obsahovat mezery, tečky, čárky, dvojtečky a další podobné znaky. Dalším omezením je, že nemůže začínat číslicí.
Pokud nahráváte data z Excelu a máte tam názvy sloupců totožné s otázkami v dotazníku (např. 15. Jaký je Váš věk?), tak vám z toho v SPSS vznikne @15JakýjeVášvěk. Takže je dobré si to připravit už v datové matici (viz video Tvorba a úprava datové matice).
1.1.2 Type (Typ)
Zde nastavíme vhodný typ proměnné. V zásadě jde o rozlišení textové nebo číselné podoby dat. Máme na výběr z následujících možností, jejichž nabídka se nám objeví po kliknutí na tři tečky v dané buňce (musíte do té buňky nejdříve kliknout).
- Numeric – používá se pro číselná data, resp. číselnou podobu kódu. Zpravidla tuto možnost využijete nejčastěji. Můžete zároveň nastavit v rámečku vedle počet míst kódu (Width) neboli zobrazovanou šířku kódu, a počet desetinných míst (Decimal places). Desetinná místa odděluje čárkou, tak jak jsme na to v ČR zvyklí.
- Comma – je stejná jako Numeric, akorát místo desetinné čárky tam budete mít tečku (tzn. místo 35,1 to bude 35.1).
- Dot – nevidím rozdíl oproti Numeric
- Scientific notation – vědecký zápis (něco ve stylu 2,7E + 0,8) – k ničemu
- Date
- Dollar
- Custom currency
- String – textová proměnná. Tzn. že data budete mít jako text, ne jako číslo. Používá se hlavně u otevřených otázek, které se nedají dobře nakódovat. Je potřeba vhodně nastavit počet znaků (Characters), aby vám to odpověď neuseklo.
- Restrictid Numeric

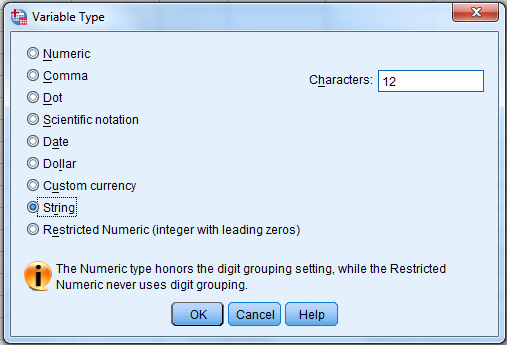
1.1.3 Width (Šířka – počet míst)
Pokud jste tak neučinili již v možnostech sloupce Type, můžete počet míst nadefinovat tady zvlášť. Znamená to prostě to, kolik míst budete potřebovat pro data v buňkách v Data View.
1.1.4 Decimals (Počet desetinných míst)
To stejné jako u Width, jen se teď jedná o desetinná místa. Tzn. nastavíme tady 2 a bude se nám v Data View zobrazovat 1,00. U zpracovávání dotazníků doporučuji nastavit zde 0, protože většinou budete mít celočíselné kódy (např. muž=1 – je zbytečné, aby se to zobrazovalo jako 1,00 – zabere to akorát místo ve výsledných tabulkách a způsobuje nepřehlednost).
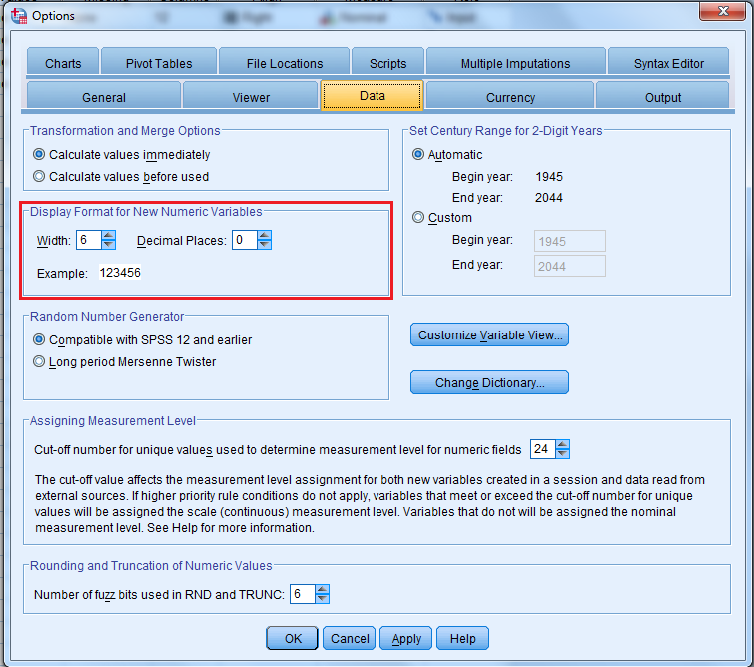
Pokud vkládáte data do SPSS přímo, můžete si v nabídce Edit – Options – záložka Data – Decimal places – nastavit počet desetinných míst, který už pak bude mít každá nová proměnná, kterou vložíte (nebudete to muset nastavovat pro každý řádek zvlášť).
1.1.5 Label (Popis proměnné)
Slouží k upřesnění názvu proměnné (Name). Labels rovněž doporučuji psát stručně, ale výstižně, protože se vám to pak bude objevovat ve výsledných tabulkách a grafech v Outputu, takže se tam moc nerozepisujte, jinak ty tabulky a grafy budou dost nepřehledné. Pokud si s přehledností či nepřehledností neděláte těžkou hlavu, tak můžete klidně použít celé znění otázky z dotazníku (což nedoporučuji – lepší je nějak vystihnout podstatu otázky).

Pokud byste přece jen chtěli mít v tom Labels delší název, ale v tabulkách a grafech stručný popis Name kvůli přehledu, existuje jedna alternativa. Když najedete na Edit – Options – záložka Output – dole najdete část „Pivot Table Labeling“. Zajímá nás ta první nabídka „Variables in labels shown as“. Hodnoty jsou tam automaticky nastavené na Labels. Můžete si tam nastavit buď jen Name nebo Name i Labels (obě jsou víceméně zbytečné, protože tam budete mít 2x v podstatě to samé). Takže si rozhodněte, zda vám v tabulkách a grafech stačí orientační krátký název (Name) nebo výstižnější popis (Label).
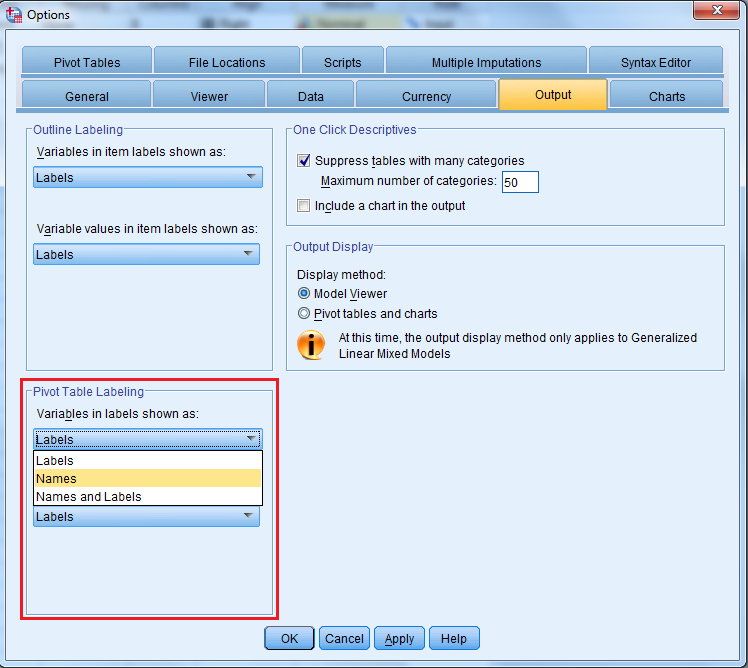
Jen pro pořádek – pokud jste se rozhodli nevyplňovat sloupec Label, tak se vám v tabulkách bude zobrazovat Name, i když máte v této nabídce zvolen Label. Je to logické – protože program nemá k dispozici Label, použije automaticky Name. V podstatě se můžete rozhodnout jestli si upravíte Name, nebo vyplníte Label, nebo oboje.
Toto nastavení platí pro všechny tabulky, které v Outputu budete generovat. Existuje ale také způsob, kterým toto nastavení můžete uplatnit jen u vybraných tabulek. To se ale provádí přímo v Outputu a budeme se tím zabývat v kapitole Možnosti zobrazení názvů tabulek a proměnných.

Asi to na přečtení není moc srozumitelné, lepší je se na tuhle část podívat na videu.
1.1.6 Values (Popis hodnot)
Patrně nejdůležitější charakteristika ze všech, protože nám umožní dát suchým kódům z datové matice lidštější popis, který nám zajistí lepší porozumění. Ve sloupci Values tedy budeme přiřazovat kódu, který jsme dali jednotlivým odpovědím v dotazníku (viz Tvorba datové matice), nějaký slovní význam. Děláme to proto, aby se nám ve výsledných tabulkách a grafech nezobrazovala pouze kódová označení, ale slovní fráze (nechceme přece v tabulkách kód pohlaví 1 nebo 2, chceme tam mít muž nebo žena).
Děláme to tak, že v řádku příslušné proměnné klikneme do pole Values, tím se nám tam objeví tři tečky, na ty klikneme a otevře se okno. Do políčka Value napíšeme kód, do políčka příslušnou slovní frázi, význam a klikneme na „Add“. Např. v případě pohlaví to bude: value=1, label=muž – add, potom value=2, label=žena – add. Takto budeme postupovat dále, dokud nepřiřadíme význam všem variantám odpovědí. Pak můžeme okno zavřít kliknutím na OK a pokračovat stejným způsobem u dalších proměnných. A ještě jedna důležitá rada. Pokud máte u více proměnných stejné kódy a odpovědi je možné zde používat funkci Ctrl + C, Ctrl + V (popř. kliknout pravým a vybrat funkci Copy a Paste). Zkopírujete nadefinované kódy u jedné proměnné a vložíte je k jiné proměnné. Ušetří vám to spoustu práce.

Vzpomínáte si, jak jsme u vysvětlování sloupce Label (viz výše) nastavovali, co se nám má zobrazovat ve výsledných tabulkách (Name nebo Label)? Podobnou možnost máme i v tomto případě. Opět dáme Edit – Options – záložka Output – teď nás ale bude zajímat ta druhá nabídka „Variable values in labels shown as“. Tady se vám může hodit ta třetí možnost (Values i Labels zároveň), na rozdíl od té druhé, která sice dokáže ušetřit nějaké místo, ale za cenu naprosté ztráty vypovídací schopnosti tabulky, protože se vám v ní budou zobrazovat jen kódy (podobně, jako kdybyste neměli vůbec nadefinované Values).


Toto nastavení platí pro všechny tabulky, které v Outputu budete generovat. Existuje ale také způsob, kterým toto nastavení můžete uplatnit jen u vybraných tabulek. To se ale provádí přímo v Outputu a budeme se tím zabývat v kapitole Možnosti zobrazení názvů tabulek a proměnných.
1.1.7 Missing (Chybějící hodnoty)
Ve výsledcích šetření se mohou objevit chyby – chybějící data, chybná data. V SPSS můžeme tyto hodnoty označit jako „Missing“ a při zpracování budou vynechány. Můžeme si je nadefinovat dle svého uvážení, když klikneme na tři tečky v příslušné buňce. Objeví se tabulka, která nám nabízí tři možnosti.
- „No missing values“ – nebudeme definovat žádné chybějící hodnoty. SPSS je vyhodnotí automaticky (prázdné buňky s tečkou v Data View).
- „Discrete missing values“ – můžeme nadefinovat maximálně tři chybějící hodnoty, kterými lze odlišit důvod jejich vzniku. Např. -3=neplatné, -2=neví, -1=není si jist.
- „Range plus one optional discrete missing value“ – definování rozsahu hodnot případně ještě jedné další hodnoty.

1.1.8 Columns (Šířka sloupce)
Zde si můžete nastavit šířku sloupců s daty v záložce Data View zadáním požadované hodnoty, což lze ale provést také přímo v Data View tažením za okraj názvu (záhlaví) sloupce.
1.1.9 Align (Zarovnání)
Zde si můžete nastavit, jakým způsobem chcete, aby se data v záložce Data View řadila. Máte na výběr Right (zprava), Left (zleva), Center (na střed).
1.1.10 Measure (Způsob měření)
Zde rozlišujeme typy proměnných z hlediska statistiky. Máme zde na výběr mezi třemi variantami: Nominal, Ordinal a Scale. V případě, že se jedná o textovou proměnnou (String), tak vybíráme pouze Nominal nebo Ordinal.
- Nominal – všechny varianty dané proměnné mají stejnou váhu. Nelze je nijak logicky seřadit. Pořadí buď neexistuje nebo by bylo nejednoznačné. Ačkoli jednotlivým variantám přidělujeme kód, nejsou nijak uspořádány. Příkladem nominálních proměnných je pohlaví, kraj, osobní priority respondenta a vyjádření názoru, rodinný stav, oblíbená barva, rodné číslo, telefonní číslo, PSČ.
- Ordinal – rozdělujeme objekty do uspořádaných tříd, kategorií, které můžeme logicky uspořádat. Kódování pak odpovídá pořadí, významnosti. Používají se pro vyjádření hodnocení, významnosti, dosažené úrovně, apod. Příkladem ordinálních proměnných může být dosažené vzdělání, vyjádření názoru na bodové škále, věkové kategorie, hodnocení typu nadprůměrný/průměrný/podprůměrný.
- Scale – oproti předchozím dvěma, tyto hodnoty jsou pouze číselné. Určují skutečnou velikost. Hodnoty (data) jsou přímo kódy, tzn. nemusíme zde používat kódování ve sloupci Values. Příkladem těchto proměnných může být věk (uváděný přímo konkrétním číslem – ne kategorie), počet dětí v rodině, počet televizorů v domácnosti, cena výrobku, průměrný příjem.
1.1.11 Role (Role proměnné)
Omlouvám se, nevím, nešahat. Automaticky je role nastavena na „Input“, tzn. vstupní nezávislá proměnná. „Target“ je výstupní závislá proměnná, „Both“ může být použita jako vstupní i výstupní proměnná, „None“ znamená bez role, „Partition“ umožňuje rozdělení dat do oddělených vzorků, „Split“ je štěpení. Ale čert ví, k čemu to všecko je. 🙂
Ne všechny sloupce pro nás mají zásadní význam, některé nám můžou spíše překážet, snižovat přehlednost záložky Variable View. Pomocí View – Customize variable view – si můžeme snadno nastavit, které sloupce se budou zobrazovat a které ne. Stačí jen zaškrtnou dané políčko.
1.2. Data View (Pohled na data)
Ve sloupcích matice máme proměnné, např. pohlaví, věk, vzdělání – zkrátka všechny otázky z dotazníku). V řádcích pak máme jednotlivé případy, např. respondenty. Pokud už máme vyplněn sloupec Values, můžeme pomocí ikony Value Labels přepínat mezi zobrazením kódů a slovních významů.

7 comments on “Pracovní prostředí SPSS 1. část – Datové okno”